Adaptive Images for Responsive Designs… Again

When I was asked to write an article for 24 ways I jumped at the chance, as I’d been wanting to write about some fun hacks for responsive images and related parsing behaviours. My heart sank a little when Matt Wilcox beat me to the subject, but it floated back up when I realized I disagreed with his method and still had something to write about.
So, Matt Wilcox, if that is your real name (and I’m pretty sure it is), I disagree. I see your dirty server-based hack and raise you an even dirtier client-side hack. Evil laugh, etc., etc.
You guys can stomach yet another article about responsive design, right? Right?
Half the room gets up to leave
Whoa, whoa… OK, I’ll cut to the chase…
TL;DR
In a previous episode, we were introduced to Debbie and her responsive cat poetry page. Well, now she’s added some reviews of cat videos and some images of cats. Check out her new page and have a play around with the browser window. At smaller widths, the images change and the design responds. The benefits of this method are:
- it’s entirely client-side
- images are still shown to users without JavaScript
- your media queries stay in your CSS file
- no repetition of image URLs
- no extra downloads per image
- it’s fast enough to work on resize
- it’s pure filth
What’s wrong with the server-side solution?
Responsive design is a client-side issue; involving the server creates a boatload of problems.
- It sets a cookie at the top of the page which is read in subsequent requests. However, the cookie is not guaranteed to be set in time for requests on the same page, so the server may see an old value or no value at all.
- Serving images via server scripts is much slower than plain old static hosting.
- The URL can only cache with
vary: cookie, so the cache breaks when the cookie changes, even if the change is unrelated. Also, far-future caching is out for devices that can change width. - It depends on detecting screen width, which is rather messy on mobile devices.
- Responding to things other than screen width (such as DPI) means packing more information into the cookie, and a more complicated script at the top of each page.
So, why isn’t this straightforward on the client?
Client-side solutions to the problem involve JavaScript testing user agent properties (such as screen width), looping through some images and setting their URLs accordingly. However, by the time JavaScript has sprung into action, the original image source has already started downloading. If you change the source of an image via JavaScript, you’re setting off yet another request.
Images are downloaded as soon as their DOM node is created. They don’t need to be visible, they don’t need to be in the document.
new Image().src = url
The above will start an HTTP request for url. This is a handy trick for quick requests and preloading, but also shows the browser’s eagerness to download images.
Here’s an example of that in action. Check out the network tab in Web Inspector (other non-WebKit development aids are available) to see the image requests.
Because of this, some client-side solutions look like this:
<img src="t.gif" data-src="real-image.jpg" data-bigger-src="real-bigger-image.jpg">where t.gif is a 1×1px tiny transparent GIF.
This results in no images if JavaScript isn’t available. Dealing with the absence of JavaScript is still important, even on mobile. I was recently asked to make a website work on an old Blackberry 9000. I was able to get most of the way there by preventing that OS parsing any JavaScript, and that was only possible because the site didn’t depend on it.
We need to delay loading images for JavaScript users, but ensure they load for users without JavaScript. How can we conditionally parse markup depending on JavaScript support?
Oh yeah! <noscript>!
<noscript>
<img src="image.jpg">
</noscript>Whoa! First spacer GIFs and now <noscript>? This really is the future! The image above will only load for users without JavaScript support. Now all we need to do is send JavaScript in there to get the textContent of the <noscript> element, then we can alter the image source before handing it to the DOM for parsing.
Here’s an example of that working … unless you’re using Internet Explorer.
Internet Explorer doesn’t retain the content of <noscript> elements. As soon as it’s parsed, it considers it an empty element. FANKS INTERNET EXPLORER. This is why some solutions do this:
<noscript data-src="image.jpg">
<img src="image.jpg">
</noscript>so JavaScript can still get at the URL via the data-src attribute. However, repeating stuff isn’t great. Surely we can do better than that.
A dirty, dirty hack
Thankfully, I managed to come up with a solution, and by me, I mean someone cleverer than me. Pornel’s solution uses <noscript>, but surely we don’t need that.
Now, before we look at this, I can’t stress how dirty it is. It’s so dirty that if you’ve seen it, schools will refuse to employ you.
<script>document.write('<' + '!--')</script>
<img src="image.jpg">
<!---->Phwoar! Dirty, isn’t it? I’ll stop for a moment, so you can go have a wash.
Done? Excellent.
With this, the image is wrapped in a comment only for users with JavaScript. Without JavaScript, we get the image. Unlike the <noscript> example above, we can get the text content of the comment pretty easily.
Hurrah! But wait… Some browsers are sometimes downloading the image, even with JavaScript enabled. Notably Firefox. Huh?
Images are downloaded in comments now? What?
No. What we’re seeing here is the effect of speculative parsing. Here’s what’s happening:
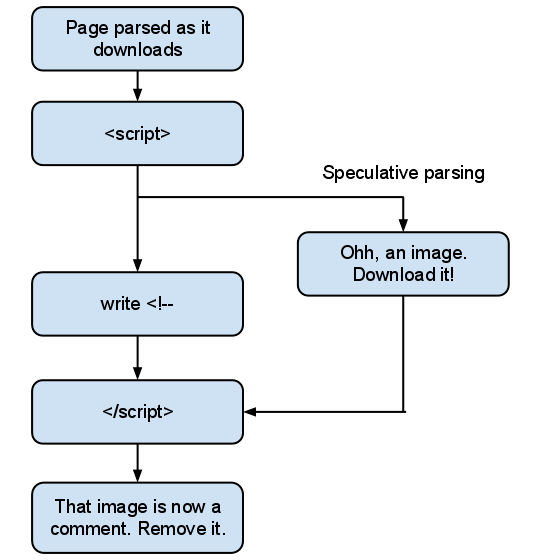
While the browser is parsing the script, it parses the rest of the document. This is usually a good thing, as it can download subsequent images and scripts without waiting for the script to complete. The problem here is we create an unbalanced tree.
 An unbalanced tree, yesterday.
An unbalanced tree, yesterday.
In this case, the browser must throw away its speculative parsing and reparse from the end of the <script> element, taking our document.write into consideration. Unfortunately, by this stage it may have already discovered the image and sent an HTTP request for it.
A dirty, dirty hack… that works
Pornel was right: we still need the <noscript> element to cater for browsers with speculative parsing.
<script>document.write('<' + '!--')</script><noscript>
<img src="image.jpg">
</noscript -->And there we have it. We can now prevent images loading for users with JavaScript, but we can still get at the markup.
We’re still creating an unbalanced tree and there’s a performance impact in that. However, the parser won’t have got far by the time our script executes, so the impact is small. Unbalanced trees are more of a concern for external scripts; a lot of parsing can happen by the time the script has downloaded and parsed.
Using dirtiness to create responsive images
Now all we need to do is give each of our dirty scripts a class name, then JavaScript can pick them up, grab the markup from the comment and decide what to do with the images.
This technique isn’t exclusively useful for responsive images. It could also be used to delay images loading until they’ve scrolled into view. But to do that you’ll need a bulletproof way of detecting when elements are in view. This involves getting the height of the viewport, which is extremely unreliable on mobile devices.
Here’s a hastily thrown together example showing how it can be used for responsive images.
I adjust the end of the image URLs conditionally depending on the result of media queries. This is done on page load, and on resize.
I’m using regular expressions to alter the URLs. Using regex to deal with HTML is usually a sign of insanity, but parsing it with the browser’s DOM parser would trigger the download of images before we change the URLs. My implementation currently requires double-quoted image URLs, because I’m lazy. Wanna fight about it?
Media querying via JavaScript
Jeremy Keith used document.documentElement.clientWidth in his example, which is great as a proof of concept, but unfortunately is rather unreliable across mobile devices.
Thankfully, standards are coming to the rescue with window.matchMedia, which lets us provide a media query string and get a boolean result. There’s even a great polyfill for browsers that don’t support it (as long as they support media queries in CSS).
I didn’t go with that for three reasons:
- I’d like to keep media queries in the CSS file, if possible.
- I wanted something a little lighter to keep things speedy while resizing.
- It’s just not dirty enough yet.
To make things ultra-dirty, I add a test element to the page with a specific class, let’s say media-test. Then, I control the width of it using media queries in my CSS file:
@media all and (min-width: 640px) {
.media-test {
width: 1px;
}
}
@media all and (min-width: 926px) {
.media-test {
width: 2px;
}
}The JavaScript part changes the URL suffix depending on the width of media-test. I’m using a min-width media query, but you can use others such as pixel-ratio to detect high DPI displays. Basically, it’s a hacky way for CSS to set a value that can be picked up by JavaScript. It means the bit that signals changes to the images sits with the rest of the responsive code, without duplication.
Also, phwoar, dirty!
The API
I threw a script together to demonstrate the technique. I’m not particularly attached to it, I’m not even sure I like it, but here’s the API:
responsiveGallery({
// Class name of dirty script element(s) to target
scriptClass: 'dirty-gallery-script',
// Class name for our test element
testClass: 'dirty-gallery-test',
// The initial suffix of URLs, the bit that changes.
initialSuffix: '-mobile.jpg',
// A map of suffixes, for each width of 'dirty-gallery-test'
suffixes: {
'1': '-desktop.jpg',
'2': '-large-desktop.jpg',
'3': '-mobile-retina.jpg'
}
});The API can cover individual images or multiple galleries at once. In the example I gave at the start of the article I make two calls to the API, one for both galleries, and one for the single image above the video reviews. They’re separate calls because they respond slightly differently.
The future
Hopefully, we’ll get a proper solution to this soon. My favourite suggestion is the <picture> element that Bruce Lawson covers.
<picture alt="Angry pirate">
<source src="hires.png" media="min-width:800px">
<source src="midres.png" media="min-width:480px">
<source src="lores.png">
<!-- fallback for browsers without support -->
<img src="midres.png" alt="Angry pirate">
</picture>Unfortunately, we’re nowhere near that yet, and I’d still rather have my media queries stay in CSS. Perhaps the source elements could be skipped if they’re display:none; then they could have class names and be controlled via CSS. Sigh.
Well, I’m tired of writing now and I’m sure you’re tired of reading. I realize what I’ve presented is a yet another dirty hack to the responsive image problem (perhaps the dirtiest?) and may be completely unfeasible in professional situations. But isn’t that the true spirit of Christmas?
No.
About the author
Jake Archibald is a developer at Lanyrd specialising in client-side stuff, although dabbles in a bit of Django. He developed Sprite Cow to help ease the pain of sprite sheets, and started a blog way after blogs stopped being cool.
Outside of the web, he’s a Formula One fan and likes taking photos of things. He tweets as @jaffathecake.
Brought to you by
Related articles
-
Being Responsive to the Small Things
Jonathan Snook considers the problem of container (or element) queries in the context of responsive web design and looks at the approach taken by current open source JavaScript solutions. Remember, no matter what size of box your Christmas gift comes in, it’s the thought that counts.
-
Making Sites More Responsive, Responsibly
Sally Jenkinson asserts that responsive design isn’t just about displaying content on multiple devices – we can also respond to users’ contextual needs to enhance experiences. When the snow lies deep and crisp and even, you’re gonna need a bigger boot.
-
Putting My Patterns through Their Paces
Ethan Marcotte dashes through the wintry landscape, his sled of flexboxed content drawn faithfully by a team of well-ordered hierarchical HTML huskies. For when it comes to structure and presentation, we must take care not to put the sleigh before the hounds.
-
Responsive Enhancement
Jeremy Keith leads us gently back to the basics of progressive enhancement with a simple navigation example. Ask yourself: does Christmas need to look exactly the same in every browser? Nope. Well, as long as you’re reading 24 ways…
-
The Responsive Hover Paradigm
Jenn Lukas twinkles like a guiding star in the deep Christmas night, casting her light on the interactivity issues raised by combined hover- and touch-enabled devices. With a little thought about designing for our content, we can add some seasonal sparkle.
-
Animating Vectors with SVG
Brian Suda dashes out a quick technique for animating SVG line drawings using JavaScript. Way better than falling snowflakes and a Santa hat on your logo.





